Transmitting data at the Ethernet 10BASE-T PHY layer
In this post I'll implement those parts of the Ethernet 10BASE-T PHY layer that are necessary to support outgoing data transmissions, and I'll turn that code into a small library that can be reused, and upon which I can build further features.
In a previous post I talked about the circuit design I'm using for my Niccle project. The post included a little bit of code to help me validate the circuit's signal response, but it stopped short of actually using the circuit to transmit data. That code was also written as a simple example binary, rather than something that could be reused in the shape of a library.
Table of Contents
A quick refresher on the PHY layer
To refresh your memory on the Ethernet 10BASE-T stack, take a look at my high-level overview of Ethernet 10BASE-T post. As a quick recap, the following parts of the Ethernet stack are at play during a data transmission at the PHY layer:
- Link test pulses (LTPs): these need to be emitted every ~16 ms to tell the device on the other side of the connection that the link is up. They aren't technically part of the packet transmission process, but without them the recipient wouldn't actually receive any data we send it.
- Manchester data encoding: this encoding mechanism is used to actually transmit packet data on the wire, and ensures that there is at least one signal level transition per transmitted data bit.
- Start of idle (TP_IDL) signal: this signal follows every data transmission, and tells the receiver that the transmission has ended.
These three parts are all that's needed to support data transmission at the PHY layer. Once we have implemented these, we can effectively offer a "channel" through which data can be transmitted on the wire, which is then used by the MAC layer. The MAC layer in turn creates structured Ethernet packets consisting of a preamble, start-of-frame delimiter (SFD), and frame/payload data and passes those to the PHY layer for transmission.
In this post I'll focus on writing a reusable library with bit banged PHY layer transmission functionality, only. I'll tackle the receiving side of the PHY layer as well as MAC layer functionality in a later post.
Library design choices
Because of the high signaling speeds required for Ethernet 10BASE-T, I'll implement the actual transmission loop in assembly, making use of the ESP32-C6's dedicated IO feature (see my previous post for more details). If that's all that interests you, you can skip ahead to the Implementing the transmission loop section. However, aside from the transmission loop there's a few other library design choices I'd like to discuss first.
Interrupt-driven link test pulses
Let's start off with the link test pulse (LTP) functionality. Before we can do anything else, we need this to be implemented robustly, so that the party on the other side of the line knows that the line is actually connected and live, and that it should listen for incoming data packets.
In my previous post I wrote a hardcoded, infinitely repeating loop that emitted the link test pulses every 16 ms. In its simplest form, that loop looks as follows:
loop
A loop which emits an LTP pulse every 16 ms, in its simplest form.
However, now that I'm getting around to actually building a small library that can be easily reused, I'd like to move away from having a single control loop that controls the timing of the LTPs, because such a loop-based approach isn't easily composable with other code.
It would mean that every time we use the library we'd need to gain and remain in control of the main thread of execution. We'd need to try and integrate the remaining application logic into the loop body, and then we'd need to very carefully ensure that that application logic never runs for longer than 16 ms, because otherwise the LTP signal timing would be off.
Instead, the task of emitting a pulse every 16 ms seems like a perfect job for an interrupt routine that is triggered by a periodic alarm. By using an interrupt we can easily decouple the LTP-management code from any of the other application code that needs to run on the chip. Emitting the LTP signal only takes a few tens of nanoseconds as well, short enough to reasonably do it directly from within an interrupt routine. All that's needed is to set up the interrupt routine and the alarm at the start of execution, and then the main thread of execution can remain free to be used for anything else.
Interface design
Now that I've decided to use interrupt-driven LTP transmissions, I can start thinking a bit about how I'd like the library to be used. The following requirements capture my main concerns pretty well at this point:
- We should use interrupt-driven LTPs.
- We should allow any GPIO pins to be used for transmitting and receiving data, and not hardcode any assumptions about the pins in the library itself.
- The ESP32-C6 chip has at least two general purpose timers, and for maximum flexibility the library shouldn't hardcode a dependency on a specific timer instance.
- We should be able to transmit packets from the main thread of execution, by calling a simple function, and ongoing data transmissions should never be interrupted by an interrupt-triggered LTP transmission.
- At a later point (not in this blog post), we should be able to read one or more received packets from the main thread as well.
- I'd like the library to fit in well with the esp-rs/esp-hal framework design,
and where possible avoid the need for blocks of unsafe code.
- In the esp-rs/esp-hal framework, peripherals like GPIO pins and timers are treated as unique, non-global resources, and Rust's borrowing rules are used to ensure exclusive mutable access to them. This means we can't just access them through a global static variable, nor can we can create multiple mutable references to them.
The following snippet of code shows the type of user experience I have in mind for the PHY layer.
An example code snippet showing how I'd like to be able to use the PHY-layer interface. Note how the LTP signal transmission is not part of the main application loop, and is instead delegated to the interrupt routine.
In reality the PHY layer of the library will probably never be used directly, and I'll instead compose a MAC layer implementation on top of it. Nevertheless, the interface shape described in the above example feels like it would layer nicely with such a MAC implementation.
Mapping the desired interface to an implementation
Because we're now dealing with interrupts things become a little more complicated: the interrupt routine from which we should emit the LTP signal needs to access the timer peripheral in order to clear its interrupt flag and to reactivate the alarm for the next time. Its functionality will, at a conceptual level, have to look something like this:
A code snippet showing what the timer interrupt routine will look like. Note how, besides transmitting the LTP signal, the interrupt routine also needs to access the actual timer instance in order to reactivate it.
While at the same time, we should ensure that the timer does not fire when we're in the middle of a transmission on the main thread of execution. The easiest way to do that is to disable the timer and interrupt before the start of the transmission, and reenable it afterwards. Something like the following:
A snippet showing what the code for transmitting a data packet will look like. Note how, besides transmitting the data signal, the function also needs to access the timer instance in order to deactivate before the transmission and then reactivate it after the transmission.
This shows the problem, however: both the interrupt routine and the
transmit_packet function need to access the shared timer instance. The
interrupt routine can also only access global static variables, so in order to
give it access to the timer instance we need to move the timer into a global
static variable as well. Both of these concerns point to the need for some form
of synchronization to ensure safe access to the shared timer instance.
Sharing resources between the main thread and interrupt routines
There's many ways we could go about this kind of sharing of resources. One way
would be to use a static mutable field (which requires unsafe blocks to
access), and enforce mutually exclusive access in an ad-hoc fashion.
However, the
critical_section
crate for no_std environments provides a nicer abstraction for exactly this
purpose, via its
Mutex
type. The mutex provides safe mutually exclusive access. Contrary to the
std::sync::Mutex type, it does not provide interior mutability, however. To
gain internal mutability it needs to be combined with the standard
core::cell:RefCell
type.
This means that we can modify the earlier interrupt routine and transmit
function to use the critical_section crates as follows:
// The global static holding the shared Timer.
//
// The Mutex provides synchronization, the RefCell provides interior mutability,
// and the Option allows us to statically initialize the variable with an empty
// value, and replace it with an actual value during initialization (since the
// Timer instance itself is not statically accessible).
static TIMER: =
new;
// Now both the interrupt routine and the code running on the main thread of
// execution can easily access the timer.
An example showing how the critical_section crate can be used to share
resources between the main thread of execution and the interrupt routine. Note
how the TIMER is a non-mutable static variable,, but how the RefCell within
nevertheless provides mutable access to the Option<Timer>.
Easy peasy! Well... that static TIMER: Mutex<RefCell<Option<Timer>>>
definition is a bit wordy, but it does do the job.
Hiding implementation details behind the interface
Last but not least, now that we've figured out how we can safely coordinate the code running in the interrupt routine with the code running on the main thread of execution, we can clean things up a bit.
For one, we can hide the Mutex<RefCell<Option>> from the consumer of the
library, by introducing a new public InterruptHandler struct whose
responsibility is to coordinate sharing of resources between the interrupt
routine and the main thread of execution, and by hiding the mutex in a private
field within that struct.
We can also move the logic to handle the timer interrupt behind a simple
InterruptHandler::on_timer_interrupt method. That way the user of the library
simply needs to configure the interrupt routine and forward the wakeups to the
InterruptHandler, but doesn't need to know exactly what happens when the
interrupt fires.
This all makes good sense to begin with, since it allows us to hide more of the implementation details from the public interface. Going back to the initial example of what it should be like to use the PHY layer library, we can adapt it to look as follows:
// The InterruptHandler struct hides the Mutex<RefCell<...>> within.
static ETH_INTERRUPT_HANDLER: InterruptHandler =
new;
A revised version of the earlier code snippet
showing what the PHY-layer interface will look like, after taking into account
that we need a static to share state between the interrupt routine and the main
thread of execution. Note how the Mutex is now hidden behind the
InterruptHandler, and how the interrupt routine now simply calls an
on_timer_interrupt method on that same handler.
This code block is basically what I ended up implementing in the project in
commit 46fcc55,
save for a few minor details like the fact that the InterruptHandler and Phy
structs need to be made generic in order for them to handle any GPIO pin and any
of the Timer instances.
Implementing the transmission loop
Now that we've got the general interface of the PHY library figured out, let's
move on to implementing the actual transmission function
(transmit_packet_inner in the
earlier code snippet). This function will receive an
Ethernet packet between 72 and 1530 octets long, and will then have to emit the
Manchester-encoded representation of those octets on the wire.
I implemented the function as a loop in assembly code, using the dedicated IO feature of the ESP32-C6 chip. The loop processes one octet of data per iteration, and each iteration consists of eight separate steps, one for each bit in the octet that needs to be emitted. The first and last steps (step 1 and 8) are distinct, since in the first step we need to do some once-per-iteration preparation, and in the last step we have to check whether we should end the loop and, if not, we have to jump backwards to start the next iteration. The steps in between (steps 2 through 7) are all identical. After the loop has ended, we then need to emit the TP_IDL signal.
This makes the transmission function look approximately as follows:
The general structure of the data transmission function transmit_packet_inner,
with a loop that emits one data octet at a time, followed by a TP_IDL emission.
Note how an octet of data is processed during each iteration of the loop by
first extracting the least significant bit (LSB), emitting the bit symbol for
that bit, shifting the octet one bit to the right, and then repeating the
process until the whole octet has been processed, after which the loop repeats.
I implemented something very similar to this in
commit 5dee569.
The main difference with the snippet above is that the real assembly code has to
use exactly the right amount of nop instructions in each step of the loop to
ensure that there is exactly 50 ns or 8 CPU cycles between each signal
transition. The code also has to be carefully arranged to ensure that the bne
branch instruction at the end of the loop falls on a 4 byte-aligned address,
which ensures that it takes exactly 3 CPU cycles when the branch is not taken
(at the end of the loop), as opposed to 4 CPU cycles when the instruction is not
properly aligned (a detail I deduced by counting CPU cycles, see
my previous post).
Manchester-encoding
The code snippet above also shows how the Manchester-encoding of data can be
implemented. The encoding is actually quite trivial to implement, since the
first half of a Manchester-encoded bit symbol is simply the data bit XOR'd by 1,
and the second half of the bit symbol is simply the data bit itself (i.e. 0 is
encoded as 10 and 1 is encoded as 01).
The simplicity of the encoding process means we can easily incorporate it directly in the transmission loop. This is great because it means we don't have to first encode the whole buffer into a second buffer, before moving on to the transmission loop.
Improving the timing behavior of the transmission loop
The implementation above is almost perfect, but it needs one more adjustment
because its timing isn't quite right yet. That's because on the ESP32-C6 chip
the bne instruction takes 2 CPU cycles when the branch is taken for the very
first time, and only 1 CPU cycle when the branch is subsequently taken again.
This means that the transmission timing for the octet emitted during the very
first iteration will always be incorrect.
Specifically, in the first iteration the last half of the last bit symbol of the octet will be held on the wire for 9 instead of 8 CPU cycles, staying low for 56.25 ns rather than 50 ns. This then pushes the subsequent octet's timing off. You can see this happen in the oscilloscope trace below, showing the start of a transmission of a 72 octet long test packet.
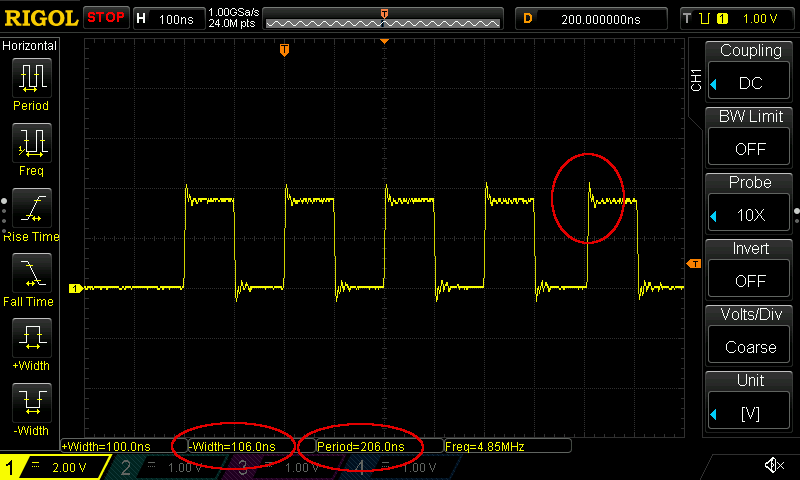
An oscilloscope trace of the start of the preamble transmission. Note how the
signal is exactly 5 MHz at first, but how after three periods of exactly 200 ns,
the fourth signal period (measured by the oscilloscope) is 206 ns instead. This
is because the bne instruction takes an extra 6.25 ns after having emitted the
last bit symbol in the first iteration's octet, which extends the low signal to
106.25 ns. You can clearly see that the 5th rising edge occurs 806.25 ns after the
first rising edge as a result, rather than occurring at exactly the 800 ns mark
as it should.
To fix this, I changed the code in commit bfcea33, so that instead of transmitting real data in the very first loop iteration, it transmits a steady zero signal during the first iteration (effectively leaving the line idle). That way we spend the first, incorrectly timed iteration not emitting any data yet, and we only start emitting data once the per-iteration timing becomes constant and predictable. You can see the result of this fix in the trace below.
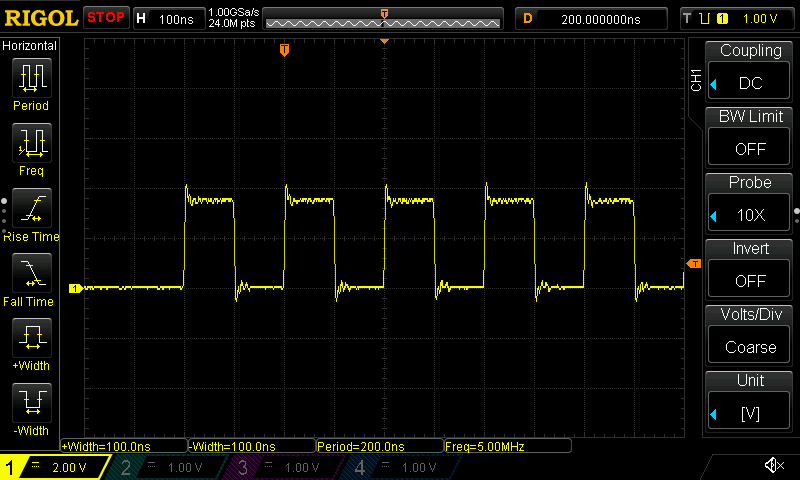
An oscilloscope trace of
the start of the preamble transmission after fixing the transmission loop to
account for the extra CPU cycle during the first taken bne branch instruction.
Note how the signal is now exactly 5 MHz throughout, and how the 5th rising edge
now aligns falls exactly 800 ns after the first rising edge.
To validate that the timing of the rest of the transmission loop is correct, we can take a look at TP_IDL signal at the end of the transmission of the 72 octet long test packet, shown below.
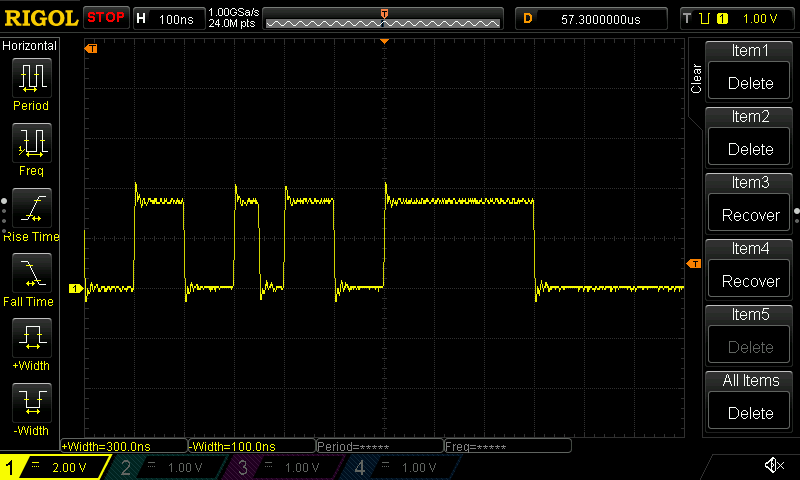
An oscilloscope trace of the end of the transmission, showing a 100 ns low signal
followed by a 300 ns high signal. The high signal last 300 ns because the last bit
in the frame check sequence (FCS) happens to be 1, and hence we see the
combination of 50 ns of high signal representing the last bit symbol half of the
FCS, followed by exactly 250 ns of high signal representing the TP_IDL
transmission.
We can see that the TP_IDL transmission timing looks accurate, as intended. We can also see that the TP_IDL signal ends 57.6 μs from the time of triggering, and looking at the earlier trace showing the preamble start, we can also see that the first rising edge occurred 200 ns before the trigger time. That first rising edge actually represents the middle of the first bit symbol of the preamble (i.e. the transmission starts with a 50 ns low signal), and hence it marks 50 ns from the true start of the transmission
Adding that all up, that gives us a total transmission duration of 57.85 μs, which is exactly the amount of time we expect a transmission of a minimum sized, 72-octet packet to take: 72 octets × 8 bits per octet × 100 ns per bit + 250 ns TP_IDL signal. This indicates that transmission the function's timing is now perfect.
Validating everything end-to-end
Everything looks good at this point, so it's time to actually test the implementation end-to-end.
To do so I handcrafted an 72 octet long test packet (the minimum Ethernet packet size): an Address Resolution Protocol request that asks whichever device has IP address 169.254.172.115 to reply with its MAC address. This handcrafted packet contains the preamble, SFD, data, padding and a pre-calculated frame check sequence. Hence, it more or less replaces the role of a full-fledged MAC layer in this test (I'll tackle that layer in a later post).
Next, I created a new
example binary
which transmits the packet (including preamble and SFD) using the PHY library's
transmit_packet method every two seconds, very similarly to the
initial interface sketch I showed above.
I then connected the microcontroller's Ethernet port to my desktop computer, which was still configured to use the Ethernet autonegotiation feature. Upon connecting the cable my computer's interface immediately detected a half-duplex 10BASE-T connection, just like when I validated the circuit design before. This indicates that the LTP functionality is still working correctly, now that we've moved it into a reusable library.
Next, I configured my desktop's Ethernet port with the static IP address
169.254.172.115, ensuring that it would respond to the hardcoded ARP request I
was using. Lastly, I then used the Wireshark project's tshark tool to inspect
the incoming traffic on my computer's port. Just as I was hoping for, it showed
the incoming test packets followed by my computer's ARP response packet:
$ tshark -i enp108s0
1 0.000000000 12:34:56:78:90:12 → Broadcast
ARP 60 Who has 169.254.172.115? Tell 169.254.172.114
2 0.000027441 Universa_e6:f8:ca → 12:34:56:78:90:12
ARP 42 169.254.172.115 is at XX:XX:XX:XX:XX:XX
3 2.003432589 12:34:56:78:90:12 → Broadcast
ARP 60 Who has 169.254.172.115? Tell 169.254.172.114
4 2.003455979 Universa_e6:f8:ca → 12:34:56:78:90:12
ARP 42 169.254.172.115 is at XX:XX:XX:XX:XX:XX
...
Success! We're transmitting our first real data!
Conclusion
We've now got a small reusable library that allows us to establish a link and transmit outbound Ethernet packets, with a convenient interface. We should also be able to extend this library fairly easily to add additional functionality, such as support for receiving inbound packets.
That's what I'll focus on in my next post, so check back again soon!