Implementing and optimizing an Ethernet 10BASE-T MAC layer for maximum throughput
In this final post in a series of posts on my Niccle project, I describe how I implemented and optimized a MAC layer on top of my bit banged Ethernet 10BASE-T PHY implementation, responsible validating packet checksums, buffering received packets, and interfacing with higher-level TCP/IP software stacks.
I'll show how my first attempt at implementing a MAC layer was functional but could only reach a download throughput of less than 10 kB/s, and exhibited a packet loss ratio of at least 30% when put under load. I'll then delve into the steps I took to optimize the implementation, which ultimately allowed me to reach a steady download throughput of about 620 kB/s, with practically no packet loss.
Let's dive in!
Table of Contents
A quick refresher
With Ethernet 10BASE-T the MAC layer is responsible for:
- Prepending the preamble to outgoing Ethernet frames, and stripping the preamble off of incoming frames.
- Appending a checksum (frame check sequence, or FCS) to outgoing frames, and validating the checksum of incoming frames.
- Enforcing a minimum inter-packet gap of 96 bit times (or 9.6 μs) between outgoing transmissions.
In addition to those responsibilities, the MAC layer also effectively forms an interface between the hardware and the software implementing higher layer protocols such as TCP/IP. Software layers frequently operate on partial MAC frames (unpadded, checksum-less frame data), and hand those off to the hardware's MAC layer for transmission.
In my previous post about receiving data at the PHY layer, I already built a very basic implementation of a MAC layer for handling incoming packets. It consisted of a single function that processed a packet received by the PHY layer's interrupt routine, stripped the preamble, checked the frame checksum, and then printed a log message to indicating whether the checksum succeeded. It didn't actually do anything else with the received packet.
This post describes how I expanded on that very basic implementation, and turned it into a full-fledged MAC layer implementation. I'll also discuss how I layered the SmolTCP TCP/IP implementation on top of that MAC layer, gaining full IP connectivity.
Implementing a most basic MAC layer
To achieve those goals, I had to do the following three things, at a bare minimum:
-
Store packets received from the PHY layer in a buffer, so they can be consumed at a later time. For comparison, the implementation in the previous post simply discarded packets after they'd been processed.
-
Provide a MAC-layer transmit function, which can calculate frame checksums and prepare Ethernet packets for the PHY layer.
-
Implement the SmolTCP
Devicetrait to hook the MAC layer up to the SmolTCP stack. This trait implementation has to read incoming frames from the RX buffer established in step 1, and transmits outgoing frames using the transmit function implemented in step 2.
Storing received packets in a buffer
My PHY layer implementation uses an interrupt routine to receive incoming packets, while I wanted to drive most of the network IO through the SmolTCP crate on the main thread of execution. This meant that whatever buffer I used to store incoming frames had to be accessible from both the interrupt routine and the main thread of execution.
I initially landed on using a
StaticThingBuf
from the thingbuf crate to store received frames. This data structure was
convenient for a number of reasons:
- It supports lock-free access by using atomic operations, allowing easy, mutex-less sharing across the interrupt routine and main thread.
- It is
no_std-compatible, as long as our target environment has support for atomic instructions, and it does not depend onalloc. - It exposes a queue interface, matching the first-in first-out (FIFO) packet consumption order which is a natural fit for a packet buffer.
- Lastly, it can efficiently
recycle
buffers after they've been consumed, and it has some advanced methods that
could allow us to avoid unnecessary copies (the
push_refandpop_refmethods). This was appealing because I had a hunch that copying packet frame data could become a significant performance bottleneck.
In this initial implementation, receiving an Ethernet frame consisted of performing the following steps within the PHY RX interrupt routine:
- The PHY layer writing the raw, unaligned packet data into a buffer owned by the PHY RX layer, and then handing the packet buffer off to the MAC layer via a callback function.
- The MAC layer finding and stripping the preamble from the raw packet data (which requires shifting most of the buffer to the left or copying it), followed by
- The MAC layer validating the checksum and, if valid,
- the MAC layer pushing (copying) the validated frame data into the
StaticThingBuffor later consumption.
This approach was fairly easy to implement, and ensured that the MAC layer RX buffer would only contain fully processed and validated frames. This seemed nice, because it meant we wouldn't waste buffer space on potentially invalid packets. After having just spent a good chunk of time getting the PHY RX implementation up and running, seeing more than a few corrupted packets along the way, this seemed like a nice benefit.
However, it did mean that I had to do an awful lot of work within the interrupt routine, and not so surprisingly this turned out to become a major sticking point later on... But let's talk about the MAC layer's TX function before diving into that!
The MAC layer transmit function
Implementing the MAC layer TX function was comparatively easier. Given some Ethernet frame data (not including the FCS), we simply have to prepend it with the preamble and start frame delimiter (SFD), calculate and append the FCS, and then pass that data to the PHY layer to be transmitted. All this runs in the main thread of execution, and only needs a single packet's worth of buffer space. Easy peasy!
The transmit function has to maintain the inter-packet gap of 9.6 μs, which we could achieve by checking how much RTC clock time has passed since the end of the last packet transmission, and then sleeping for however many microseconds are needed to create the necessary gap. I truth, I haven't actually gotten around to implementing this yet, since my implementation seems to have a sufficient amount of overhead to keep outgoing packet transmissions sufficiently separated. It's still something I plan to fix up in a later change, however.
Connecting the MAC layer to SmolTCP
Now that I had a functional MAC layer, is was quite easy to connect to SmolTCP. By using SmolTCP I could then start benefiting from all of the functionality it offered (e.g. an ARP protocol implementation for IP-to-MAC address resolution, a DHCP implementation, a TCP implementation, etc.). I was particularly interested in using it to test the performance of my PHY & MAC implementation.
SmolTCP's
Device trait
connects it to a MAC layer, and it consists of three functions:
capabilities(): for describing the type and capabilities of the MAC layer, such as whether it's an Ethernet or Wifi MAC layer,receive(...): for receiving packets,transmit(...): for transmitting packets.
It's worth noting that receive and transmit functions are "lazy", if you
will: instead of returning the received data or transmitting the given data
right away, they return an RxToken or TxToken with which SmolTCP can
actually consume the received data or transmit outgoing data. This structure
allows SmolTCP to avoid making unnecessary copies, at the cost of slightly
complicating the implementation of the trait.
Testing the MAC layer with ping and HTTP
Now that I had a basic MAC implementation (implemented in commit 69642b8), hooked up to a the SmolTCP TCP/IP library (implemented in commit f3ea94c), I was finally able to write some better benchmarking binaries!
Note that during each of the tests below, my computer's Ethernet connection was configured to have a link-local IP address, and that the controller's auto-negotiation function determined the link to be half-duplex (as discussed in my previous post). I did also try forcing the link to be full-duplex, but this had a fairly negligible effect on my results.
Ping
It thought a good first test of the whole stack would be to issue a few ping
requests and monitor their responses. This would test all of the basic
components of the PHY and MAC layers, as well as the SmolTCP integration,
allowing me to monitor for packet loss, without immediately trying to push a
large amount of bandwidth, through the stack. Nor would it involve long bursts
of consecutive outgoing/incoming packets, something I was pretty sure my
unoptimized implementation wouldn't handle well yet.
I implemented such a test in the
smoltcp_ping
example binary, basing it on the
example
provided by the SmolTCP project. Most of the code in the example binary is
actually SmolTCP boilerplate, setting up the host IP address and routing rules,
socket buffers, etc., with just a little bit of Niccle-specific configuration at
the top.
Once all of that was set up, I could finally see my Ethernet implementation come to life!
INFO - Booted up!
INFO - 40 bytes from 169.254.172.115: icmp_seq=0, time=2.9 ms
INFO - 40 bytes from 169.254.172.115: icmp_seq=1, time=1.5 ms
INFO - 40 bytes from 169.254.172.115: icmp_seq=2, time=1.4 ms
INFO - 40 bytes from 169.254.172.115: icmp_seq=3, time=1.4 ms
INFO - 40 bytes from 169.254.172.115: icmp_seq=4, time=1.3 ms
INFO - 40 bytes from 169.254.172.115: icmp_seq=5, time=1.4 ms
INFO - 40 bytes from 169.254.172.115: icmp_seq=6, time=1.4 ms
INFO - 40 bytes from 169.254.172.115: icmp_seq=7, time=1.4 ms
INFO - 40 bytes from 169.254.172.115: icmp_seq=8, time=1.4 ms
INFO - 40 bytes from 169.254.172.115: icmp_seq=9, time=1.4 ms
INFO - --- 169.254.172.115 ping statistics ---
INFO - 10 packets transmitted, 10 received, 0% packet loss
INFO - --- Stats ---
INFO - PHY TX: Packets: 11, LTPs: 118
INFO - PHY RX: Packets: 11, trunc: 0, LTPs: 106
INFO - MAC RX: Packets: 11, invalid SFD: 0, invalid CRC: 0
INFO - Consumed: 11, dropped: 0
... after having issued 500 such ping requests ...
INFO - --- 169.254.172.115 ping statistics ---
INFO - 10 packets transmitted, 10 received, 0% packet loss
INFO - --- Stats ---
INFO - PHY TX: Packets: 503, LTPs: 5949
INFO - PHY RX: Packets: 503, trunc: 0, LTPs: 5299
INFO - MAC RX: Packets: 503, invalid SFD: 0, invalid CRC: 0
INFO - Consumed: 503, dropped: 0
We can see that the ping test went smoothly, and that all requests receive a response, without any noticeable packet loss, even after 500 ping requests. So far so good!
Downloading payloads with HTTP GET requests
I wanted my next test to be more of an actual stress test, giving me better
sense of how the implementation behaved under more load. So I wrote another
smoltcp_http_get
example binary which downloads a payload using an HTTP GET request. Again, I
initially worked off of another
example
in the SmolTCP repo.
The HTTP protocol is built on top of TCP, and I knew that as long as the payload was at least multiple kilobytes in size (i.e. larger than the 1500 bytes that can fit in an Ethernet frame), this type of test would tell me how well the implementation could handle bursts of multiple sequential incoming packets.
As you might have guessed, the results weren't that great...
INFO - Booted up!
INFO - === Issuing 5 HTTP GET requests for /10 kB.txt
INFO - Received 10068 bytes over 3.302 s (3.0 kB/sec) with CRC32 2361199371
INFO - Received 10068 bytes over 1.526 s (6.6 kB/sec) with CRC32 2361199371
INFO - Received 10068 bytes over 1.495 s (6.7 kB/sec) with CRC32 2361199371
INFO - Received 10068 bytes over 1.523 s (6.6 kB/sec) with CRC32 2361199371
INFO - Received 10068 bytes over 1.519 s (6.6 kB/sec) with CRC32 2361199371
INFO - --- Stats ---
INFO - PHY TX: Packets: 71, LTPs: 620
INFO - PHY RX: Packets: 110, trunc: 2, LTPs: 578
INFO - MAC RX: Packets: 66, invalid SFD: 30, invalid CRC: 14
INFO - Consumed: 66, dropped: 0
INFO -
INFO - === Issuing 5 HTTP GET requests for /100 kB.txt
INFO - Received 100069 bytes over 6.143 s (16.3 kB/sec) with CRC32 3505040786
INFO - Received 100069 bytes over 9.449 s (10.6 kB/sec) with CRC32 3505040786
INFO - Received 100069 bytes over 34.526 s (2.9 kB/sec) with CRC32 3505040786
INFO - Received 100069 bytes over 21.241 s (4.7 kB/sec) with CRC32 3505040786
INFO - Received 100069 bytes over 18.032 s (5.5 kB/sec) with CRC32 3505040786
INFO - --- Stats ---
INFO - PHY TX: Packets: 514, LTPs: 5972
INFO - PHY RX: Packets: 635, trunc: 9, LTPs: 5588
INFO - MAC RX: Packets: 444, invalid SFD: 147, invalid CRC: 44
INFO - Consumed: 444, dropped: 0
INFO -
INFO - === Issuing 5 HTTP GET requests for /1 MB.txt
INFO - Received 1000070 bytes over 74.507 s (13.4 kB/sec) with CRC32 2795970732
INFO - Received 1000070 bytes over 117.718 s (8.5 kB/sec) with CRC32 2795970732
^C
As we can see the requests did succeed, and they received the same response data each time (indicating the implementation at least wasn't silently corrupting the data it returned).
However, the throughput I observed was pretty horrendous, varying from 16.3 kB/s when I was lucky down to as low as 2.9 kB/s. This meant that once we got to the 1 MB payload sizes each request starting taking more than a minute, at which point I cut the run short. This really is quite slow. The 10BASE-T protocol's theoretical throughput is more than 1 MB/s, yet for many requests I wasn't even able to reach more than 1% of that!
I was happy to be able to show some level of functionality at my first attempt, but I'd definitely set my hopes higher than this. So onto debugging it was!
Diagnosing the bottlenecks.
Luckily, I'd had the foresight of gathering some basic stats at both the PHY and MAC layers, counting the number of valid and invalid packets. We can see from the connection stats in the output above that the implementation was observing lots of invalid Ethernet packets, whether ones that were truncated at the PHY layer, or ones that couldn't be aligned or CRC-validated by the MAC layer, indicating that something seemed to be going horribly wrong. By the PHY layer's own accounting this added up to about 30% packet loss (based on 444 valid packets out of a total of 635), and that was probably an underestimate.
The HTTP protocol is built on top of the TCP protocol, which can handle and correct for lost or corrupted packets quite well. Each received TCP packet needs to be acknowledged by the recipient, and if the sender does not see an acknowledgment after a certain amount of time has passed, it concludes that the corresponding packet was dropped and retransmits that packet. The TCP protocol also makes use of a 'receive window' concept to try and avoid sending more data to a device than it can actually handle, which helps to avoid devices dropping packets in the first place.
This makes the TCP protocol quite robust, even over unreliable connections, but only within certain limits. Indeed, it's quite impressive that we were able to complete any of the HTTP requests at all given such high packet loss numbers.
Using Wireshark on my desktop to take a look at what was actually going on, my hunch was quickly confirmed. Our device was causing tons of packet retransmissions from the server.
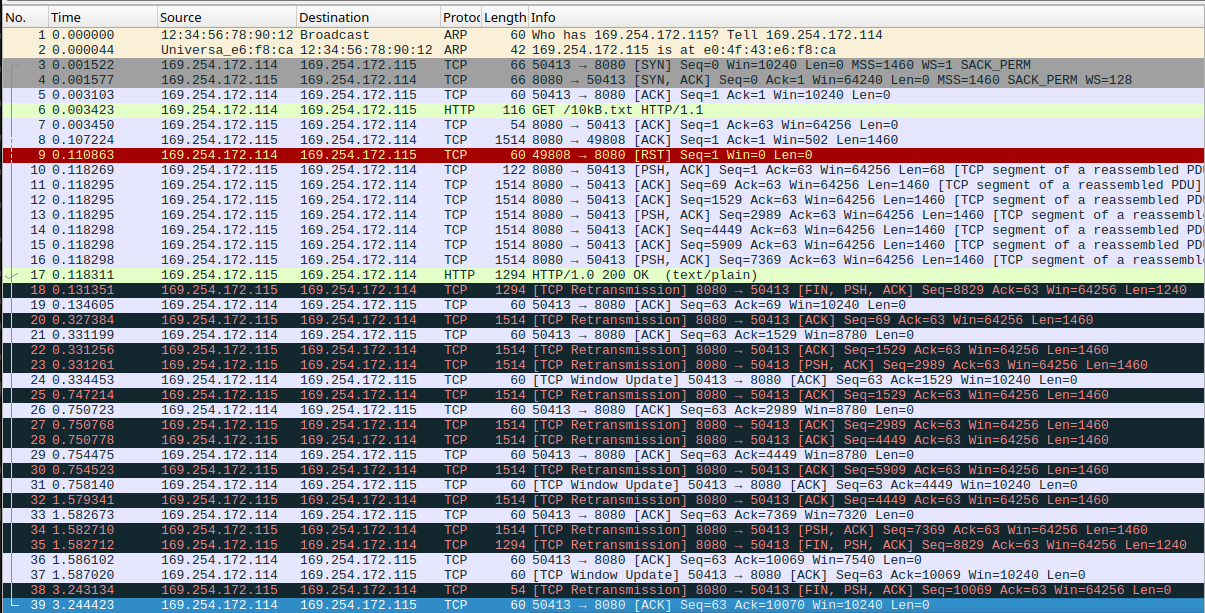
A packet capture for a GET request for the 10 kB payload. Note how between packet 8 to 17 the server sends the whole payload in practically single burst of packets. This is followed by a long sequence of packet retransmission attempts, until the device has finally ACKed all of the data and the connection is closed.
We can see that once the connection is established, the server sends a burst of 8 large packets to our device, yet it takes another 12 packet retransmissions for our device to finally ACK all of the data!
These retransmissions are deadly to the throughput of the connection. For starters, they mean that data has to be retransmitted multiple times. But more importantly, each retransmission occurs only after the sender has waited for a certain amount of time and decided that the packet must have been lost. The sender progressively increases these delays, giving the receiver more time to respond after each retransmission attempt, and this causes the throughput to drop severely.
When looking more closely, I could see that the device was only acknowledging the first packet in each burst of packets, and then ignoring all of the remaining packets in the burst. Upon retransmission the sender would send another (smaller) burst of packets, and the same thing would happen. This hinted at the fact that the device's RX implementation was underperforming, causing it to drop (i.e. ignore) incoming packets.
Improving the throughput
With this realization, I took a closer look at the MAC and PHY RX code paths.
Remember how earlier on I described how the MAC RX implementation would perform multiple steps per packet (alignment, validation, copying of the validated data into the MAC RX buffer), all while running the RX interrupt routine? This was a convenient way to structure the code, and the fastest path to an initial implementation, but it turns out that it was also horribly inefficient.
At first I was pretty optimistic, and I figured I knew why it was so inefficient: I figured that aligning the packet (a copy) and calculating its checksum were simply taking too much time. So in my first optimization attempt, I changed the code to push the raw, unaligned data into the MAC RX buffer, and to only align and validate that data outside of the interrupt routine, on the main thread.
This, however, didn't really improve the situation at all. It was time to pull out the oscilloscope again.
So I decided to establish a baseline first. I reset my workspace back to the initial implementation, and I added some instrumentation to the code in the RX interrupt routine, having it emit some pulses at the start of the routine as well as at the end.
As you can see on the screenshot below we were taking a lot more than 15 μs!
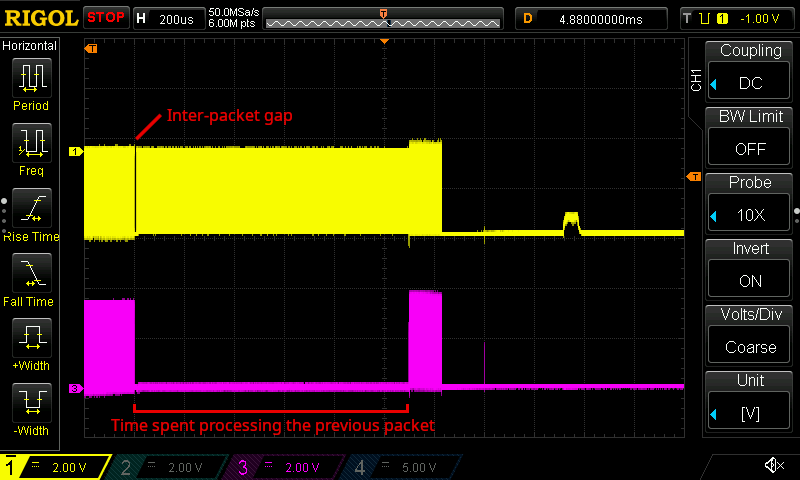
An oscilloscope trace showing the tail end of one incoming packet signal followed by another packet signal (top), as well as a corresponding debug signal (bottom). The debug signal shows a long pause of approximately 1050 μs after the end of the first packet, which is the time it took for the MAC RX layer to process that packet. It then shows activity again, corresponding to the interrupt routine being invoked again in response to the tail end of the next incoming packet.
The screenshot shows the signal for two consecutive incoming packets at the top, and the tiny highlighted gap is the 9.6 μs inter-packet gap. The signal at the bottom tells us that it took the MAC RX layer 1050 μs to process the previous packet. You can also see how after processing the first packet the interrupt routine is invoked again in response to the (truncated) remainder of the second packet. This actually explains why the connection stats reported so many truncated packets.
So at this point I knew I was taking about 100 times too long to process each packet. Not so great indeed.
Now, why was it actually taking so much time? It turns out there were two major reasons for it, each of which I'll discuss in more detail below:
- us doing too much work in the interrupt routine, aligning the data and validating checksum (i.e. my first hunch), and
- even a single
memcpyoperation on a full length packet taking too long, and - code having to be loaded from flash storage into RAM, mid-interrupt.
My first hunch was right, and so I returned back to offloading as much of the
processing of the raw packet data to the main thread. In fact, after making
those changes and ensuring that the memcpy function was placed in RAM (see
below for more details) it already brought the post processing latency down to
about 16.25 μs or so, as shown below.
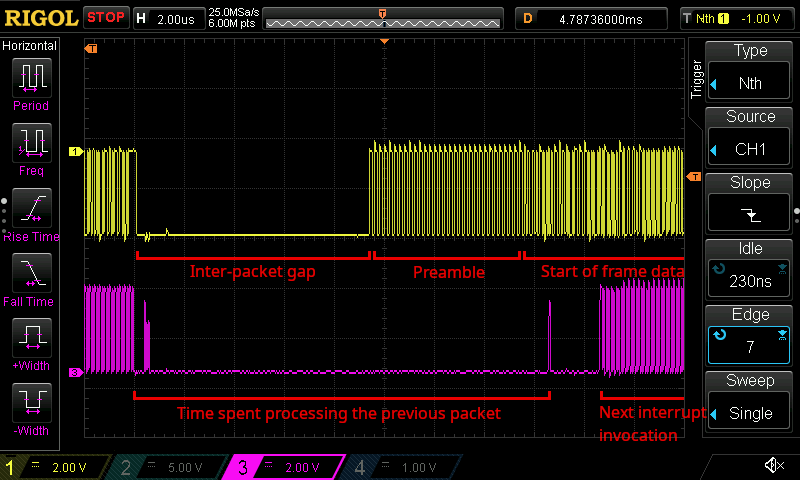
An oscilloscope trace showing the tail end of one incoming packet signal followed by another packet signal (top), as well as a corresponding debug signal (bottom). Note the horizontal scale is much smaller now. The debug signal now shows a much shorter MAC RX processing time of approximately 16.5 μs, yet this is still too long as it still places the next interrupt invocation well past the start of the next frame.
Even though this already meant we were taking only 1.5% of the time it originally took to process a single packet, it still meant that the interrupt for the next packet would fire too late, and we'd still see truncated data as a result. This explains why when I tried these initials optimizations earlier on, I didn't actually see any major improvement to the throughput at all.
Avoiding memcpy operations
The single remaining copy operation, from the PHY layer's buffer into the MAC layer's RX queue buffer, was simply still taking too long. Specifically, I measured it taking close to 14 μs.
While that's not quite the 15.2 μs we technically have available, it nevertheless allows not nearly enough time for the everything else that needs to run in the interrupt routine (the other 2.5 μs or so in the above screenshot). For example, I established in my previous post that just invoking the interrupt routine in response to the next incoming packet already takes close to 750 ns. We also need to account for additional bits of overhead here and there in the interrupt routine, which easily add up to another 1 μs or more.
Just to check whether this 14 μs number really made sense, I took a closer look
at the instructions that make up a memcpy. On RISC-V even the simplest
implementation requires 5 instructions to copy a single word (in this is
basically what you'll see in the objdump output for memcpy):
- one to load a word (4 bytes) of data from the source buffer,
- one to write a word of data to the destination buffer,
- two to increment both buffer pointers,
- and one to conditionally branch back to the start of the loop.
Optimistically assuming 6.25 ns per instruction (given the ESP32-C6's 160 MHz clock speed), that's 31.25 ns per 4 bytes of data. However, when we have to copy 1526 bytes of data (a full length packet), that adds up to about 11.9 μs (5 instructions × 6.25 ns × 1526 bytes ÷ 4 bytes per word). And that's assuming each instruction only takes one CPU cycle.
Indeed, if we assume 6 CPU cycles per iteration, we arrive at a total of 14.3 μs per copy, more or less what I measured in practice. This really made clear that I had to optimize the interrupt routine as much as possible, and that I was going to have to remove this copy operation.
I achieved this by making the PHY RX layer request buffer space from the MAC RX layer at the start of the RX interrupt routine. This way the PHY layer could write directly into the final destination buffer, and I could avoid having to copy from the PHY's private RX buffer into the MAC RX buffer.
Switching to the bbqueue bip buffer crate
This brings me to another wrinkle I now had to solve.
The RX interrupt routine is invoked for every incoming RX signal, which means it's invoked for every link test pulse, as well as for actual packet transmissions. The interrupt routine invokes the PHY RX receive loop which is written in assembly, and which writes data to the buffer, but only if it detects an actual incoming packet. If the receive loop detects that it was woken up because of an LTP, it ignores the transmission and it doesn't write anything to the buffer.
But, now that I'd structured the code to request a buffer from the MAC layer's
StaticThingBuf at the start of each interrupt routine invocation, this meant
that I'd be allocating a buffer for each incoming LTP signal unnecessarily. And
to make matters worse, the StaticThingBuf data structure does not allow
"cancelling" a previously requested buffer, since it only allows pushing to the
head of the queue and popping from the tail of the queue (a strict FIFO order).
This meant that we'd quickly fill the StaticThingBuf with empty entries.
Luckily, it was at this point that I found the
bbqueue crate. This crate implements a
Single Producer Single Consumer (SPSC) queue using a bipartite circular buffer,
or
bip buffer.
A bip buffer is a type of circular buffer that allows allocating contiguous
blocks of memory of variable length. The bbqueue implementation is also
no_std compatible and lock-free, again using atomic operations to ensure safe
concurrent, just like the thingbuf crate.
Most important of all, its API is such that you first request a buffer of a given size, write data to it, and only then commit that buffer (or a subslice of the buffer). This means that you can allocate a buffer and then cancel it if you didn't end up needing it, exactly what we need to handle those pesky LTP interrupt routine wakeups.
It also means that you can allocate a full-length buffer, and then commit only
the number of bytes you actually ended up using in that buffer. For example, we
can allocate enough buffer space to hold a full-length packet at the start of
the interrupt routine, but only commit a fraction of that space if we only end
up receiving a minimum-length Ethernet packet in the end. Compare this to the
thingbuf crate, which required us to always allocate a full-sized buffer of
1526 bytes for every packet, even if it only held 72 bytes of packet data.
Lastly, the bbqueue API provides a convenient
framed mode of
operation, which makes producing and consuming chunks of variable sizes easier.
It made the bbqueue crate just what I needed, and I replaced all use of the
thingbuf crate with the bbqueue crate.1
Avoiding blocking on flash storage
Having a copy-less implementation made things work a lot better, but I was still
noticing some inconsistent/unpredictable timing behavior in the interrupt
routine that was leading to packet loss. For example, it seemed that sometimes
even the bbqueue functions for requesting or committing a new buffer were
taking too long.
Given my previous experience with unexpectedly slow code on the ESP32-C6 chip, I
had a hunch this was due to having to read the code instructions from flash
storage mid-execution.2 One way to avoid this problem is to
ensure that performance-critical code is always kept in the chip's RAM. This is
easier said than done, however. Up until now I had already ensured that most of
the PHY layer's code was kept in RAM using the
#[ram]
attribute provided by the esp-rs/esp-half framework. However, that attribute
can't be applied to code we don't own (e.g. code in the bbqueue or smoltcp
crate).
So to work around that problem, I wrote a simple
linker script
that ensures that various performance critical functions are placed in a
separate binary section that is always kept in RAM (this is how the #[ram]
attribute is actually implemented as we: it's simply an alias for the
#[.link_section = ".rwtext"] attribute).
The combination of these three changes (most of them implemented in commit a53ea4e) finally made the RX interrupt routine sufficiently performant, with it taking only a little bit more time at the start to allocate the RX buffer, and only a little bit of time at the end to "commit" that buffer.
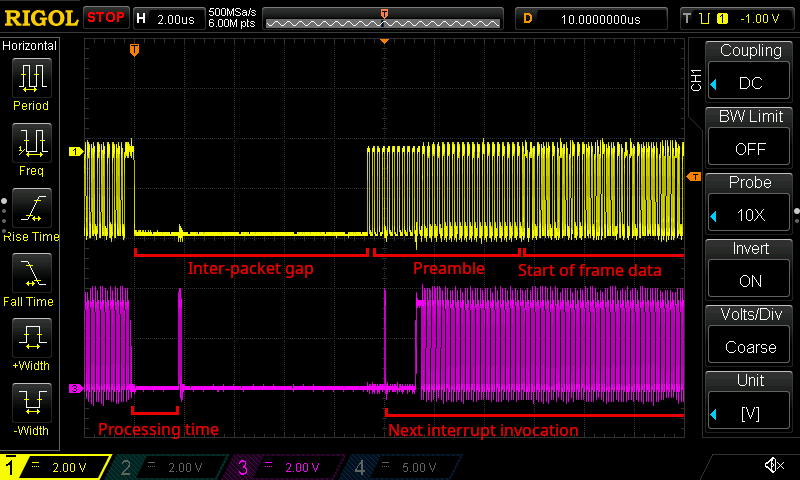
An oscilloscope trace showing the tail end of one incoming packet signal followed by another packet signal (top), as well as a corresponding debug signal (bottom). The debug signal now shows very short MAC RX processing time of just 2 μs or so.
As the screenshot shows, we were now only taking about 2 μs to post-process a packet, leaving plenty of time for the interrupt routine to handle the next incoming packet.
Leveraging TCP flow control
One last improvement I made was to optimize the TCP receive window reported by my device, to ensure we could actually benefit from TCP's flow control mechanism to the fullest extent possible.
In my initial implementation I had allocated enough buffer space in the MAC RX
queue to hold 10 full length frames, with the intuition that we'd need enough
buffer space to store at least a few consecutive incoming packets, and 10 felt
about right. Similarly, when configuring the SmolTCP TCP socket in the
smoltcp_http_get example binary, I'd allocated a similar amount of (separate)
SocketBuffer
space. The sizes of these buffers didn't really matter much initially, since the
initial MAC implementation was so inefficient that we never were really able to
receive multiple packets in a burst sequence anyway, so the buffer filling up
was never the real bottleneck.
However, now that I'd optimized the RX interrupt routine, I was actually getting to a point where I could fill up the MAC RX buffer if a long enough burst of packets arrived. At this point packets would start being dropped again, which would again negatively affect the throughput.
I found I could achieve maximum throughput by ensuring that the SmolTCP
SocketBuffer size was somewhat smaller than the MAC RX buffer size. This is
because SmolTCP uses the TCP RX SocketBuffer size to determine the TCP receive
window it reports to the sender. By ensuring that it reports a somewhat smaller
TCP receive window than we actually have room for in the MAC RX packet queue, it
prevents the sender from sending more packets than we could actually store.
After finding this configuration sweet spot, I managed to reach a point where:
-
The interrupt routine basically runs non-stop while a burst of packets is arriving.
-
Then, once the sender knows that it has filled up the receive window and stops sending more packets, the main thread is able get some CPU time again.
-
At this point the SmolTCP layer consumes all of the packets in the MAC RX queue, ACKing each of those packets to the sender (reporting the newly freed up receive window along the way).
-
At that point the sender can send another bursts of packets, and the whole process repeats.
In short, TCP flow control was now working as it should, automatically limiting the sender's throughput to what our device could actually handle. The next section will include some packet captures showing this exact process in action.
Measuring the improved throughput
After all of these changes, both the ping and HTTP GET example showed significant improvements. Let's start with the ping example first.
INFO - Booted up!
INFO - 40 bytes from 169.254.172.115: icmp_seq=0, time=1.8 ms
INFO - 40 bytes from 169.254.172.115: icmp_seq=1, time=0.6 ms
INFO - 40 bytes from 169.254.172.115: icmp_seq=2, time=0.8 ms
INFO - 40 bytes from 169.254.172.115: icmp_seq=3, time=1.0 ms
INFO - 40 bytes from 169.254.172.115: icmp_seq=4, time=1.0 ms
INFO - 40 bytes from 169.254.172.115: icmp_seq=5, time=0.9 ms
INFO - 40 bytes from 169.254.172.115: icmp_seq=6, time=0.9 ms
INFO - 40 bytes from 169.254.172.115: icmp_seq=7, time=0.9 ms
INFO - 40 bytes from 169.254.172.115: icmp_seq=8, time=0.7 ms
INFO - 40 bytes from 169.254.172.115: icmp_seq=9, time=0.6 ms
INFO - --- 169.254.172.115 ping statistics ---
INFO - 10 packets transmitted, 10 received, 0% packet loss
As shown, the round-trip latency per ping request was reduced from about 1.4 ms to 1 ms or less. This is likely driven by the change that ensured that performance critical code is now always resident in RAM.
Now let's take a look at the HTTP GET example.
INFO - Booted up!
INFO - Created MAC instance!
INFO - === Issuing 5 HTTP GET requests for /10 kB.txt
INFO - Received 10068 bytes over 3.983 s (2.5 kB/sec) with CRC32 2361199371
INFO - Received 10068 bytes over 0.017 s (592.2 kB/sec) with CRC32 2361199371
INFO - Received 10068 bytes over 0.020 s (503.4 kB/sec) with CRC32 2361199371
INFO - Received 10068 bytes over 0.020 s (503.4 kB/sec) with CRC32 2361199371
INFO - Received 10068 bytes over 0.018 s (559.3 kB/sec) with CRC32 2361199371
INFO - --- Stats ---
INFO - PHY TX: Packets: 23, LTPs: 311
INFO - PHY RX: Packets: 55, trunc: 0, LTPs: 288, OOM: 0
INFO - MAC RX: Packets: 55, invalid SFD: 0, invalid CRC: 0
INFO - Valid: 55
INFO -
INFO - === Issuing 5 HTTP GET requests for /100 kB.txt
INFO - Received 100069 bytes over 0.164 s (610.2 kB/sec) with CRC32 3505040786
INFO - Received 100069 bytes over 0.163 s (613.9 kB/sec) with CRC32 3505040786
INFO - Received 100069 bytes over 0.163 s (613.9 kB/sec) with CRC32 3505040786
INFO - Received 100069 bytes over 0.163 s (613.9 kB/sec) with CRC32 3505040786
INFO - Received 100069 bytes over 0.163 s (613.9 kB/sec) with CRC32 3505040786
INFO - --- Stats ---
INFO - PHY TX: Packets: 173, LTPs: 313
INFO - PHY RX: Packets: 415, trunc: 0, LTPs: 290, OOM: 0
INFO - MAC RX: Packets: 415, invalid SFD: 0, invalid CRC: 0
INFO - Valid: 415
INFO -
INFO - === Issuing 5 HTTP GET requests for /1 MB.txt
INFO - Received 1000070 bytes over 1.618 s (618.1 kB/sec) with CRC32 2795970732
INFO - Received 1000070 bytes over 1.605 s (623.1 kB/sec) with CRC32 2795970732
INFO - Received 1000070 bytes over 1.604 s (623.5 kB/sec) with CRC32 2795970732
INFO - Received 1000070 bytes over 1.616 s (618.9 kB/sec) with CRC32 2795970732
INFO - Received 1000070 bytes over 1.618 s (618.1 kB/sec) with CRC32 2795970732
INFO - --- Stats ---
INFO - PHY TX: Packets: 1643, LTPs: 316
INFO - PHY RX: Packets: 3855, trunc: 0, LTPs: 292, OOM: 0
INFO - MAC RX: Packets: 3855, invalid SFD: 0, invalid CRC: 0
INFO - Valid: 3855
INFO -
INFO - === Issuing 5 HTTP GET requests for /3 MB.txt
INFO - Received 3000070 bytes over 4.846 s (619.1 kB/sec) with CRC32 2966222055
INFO - Received 3000070 bytes over 4.851 s (618.4 kB/sec) with CRC32 2966222055
INFO - Received 3000070 bytes over 4.855 s (617.9 kB/sec) with CRC32 2966222055
INFO - Received 3000070 bytes over 4.839 s (620.0 kB/sec) with CRC32 2966222055
INFO - Received 3000070 bytes over 4.829 s (621.3 kB/sec) with CRC32 2966222055
INFO - --- Stats ---
INFO - PHY TX: Packets: 6053, LTPs: 319
INFO - PHY RX: Packets: 14146, trunc: 0, LTPs: 294, OOM: 0
INFO - MAC RX: Packets: 14146, invalid SFD: 0, invalid CRC: 0
INFO - Valid: 14146
INFO -
As shown, we now reached a significantly higher throughput of around 620 kB/s, much better than the 10-20 kB/s or so we managed before. This means we're now getting around 50% of the maximum throughput you can theoretically achieve with a 10BASE-T connection, which is about 1,250 kB/s. This is pretty decent, given that we have spend at least some amount of CPU time processing the incoming packets and sending out responses. Not only are we reaching a very decent throughput now, but not a single packet seems to have been lost either! (At least not in any way the receiver was able to observe.)
Looking at a Wireshark packet capture for the GET requests for the 10 kB payload again, we can see that this is because the TCP protocol is now operating much more effectively.
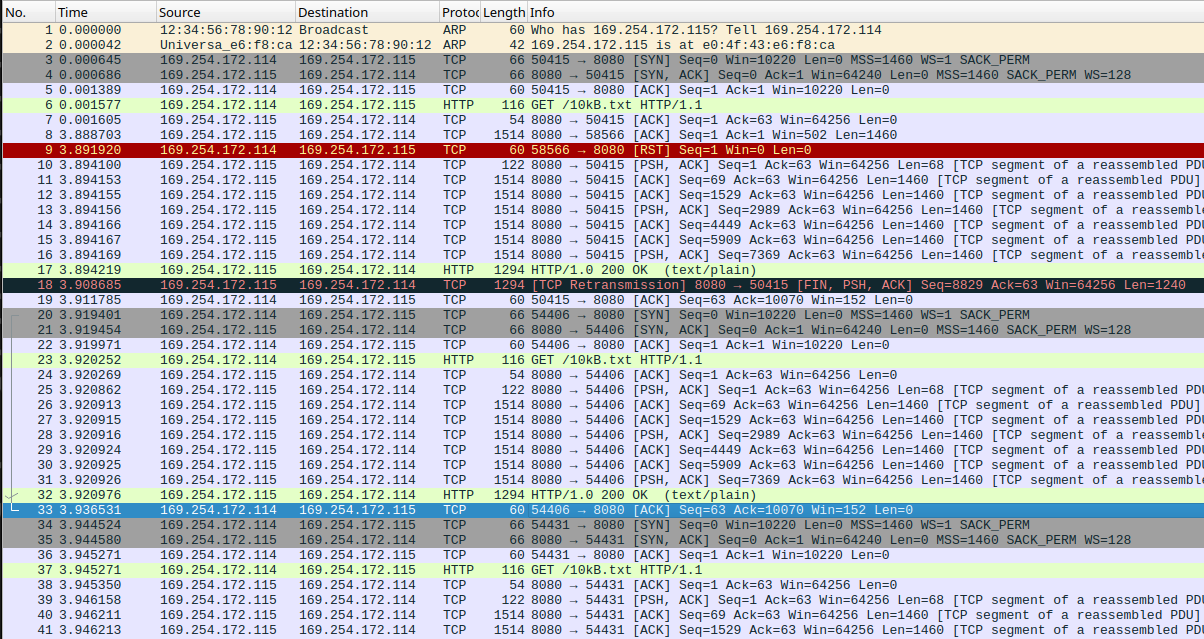
Another packet capture showing two consecutive GET requests for the 10 kB payload, using the newly optimized code. Note how the server again sends the whole payload in a single burst from packet 8 to 17. However, this time the device confirms receipt of all this data in a single ACK in packet 19, after which the next GET request follows in similar fashion.
At the start of the connection the sender again sends an initial burst of packets, which now all fit within the receiver's buffer space thanks to the more accurately reported receive window. We can see all of the packets getting ACKed by the receiver via a single ACK packet, followed by the next TCP connection for the next GET request being established.
Note that the packet capture shows that there was now only one packet retransmission, which in fact seems to have been redundant anyway. The sender likely believed that enough time had passed that the initial packet was lost, but in fact our device was simply taking a little longer than expected to work through all the packets in the RX queue before sending an ACK packet to acknowledge their receipt.
The whole 10 kB payload fit within a single burst of packets, so let's also look at the larger 100 kB payload's packet capture to see how the device handles an even higher load.
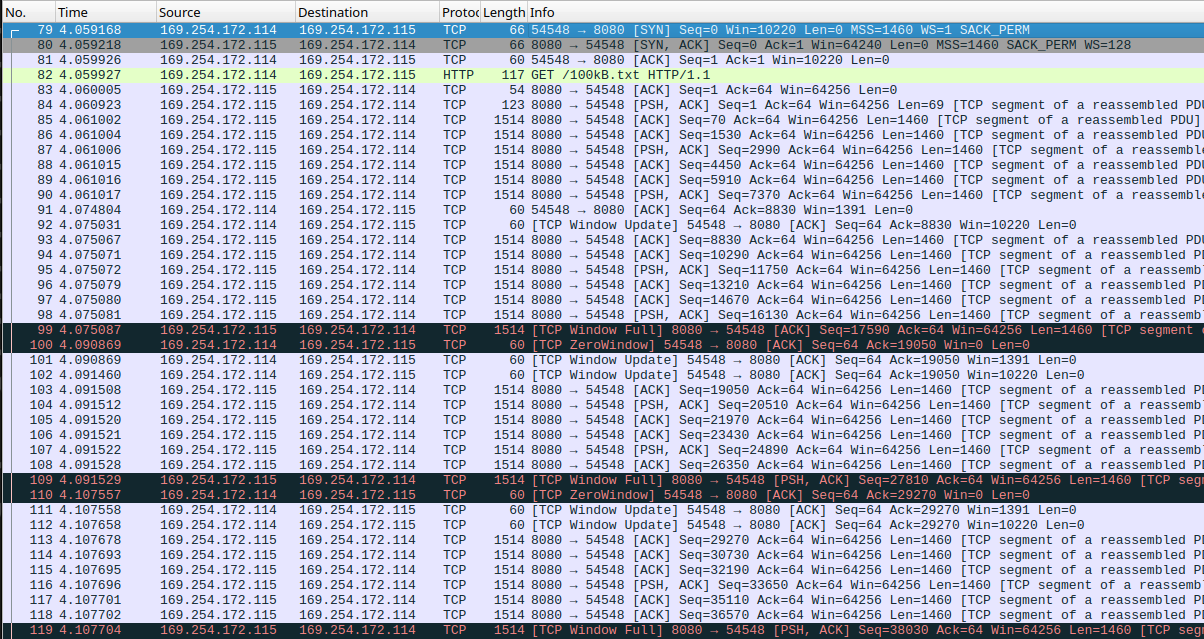
Another packet capture showing a GET request for the 100 kB payload, this time showing TCP flow control in action. The server sends a burst from packet 85-90, followed by two device ACKs in packets 91-92. This is followed by another burst of exactly 7 maximum-length packets from packets 93-99, filling the device's receive window completely. This is followed by a set of 3 ACKs in packets 100-102, after which the process repeats.
We can see the TCP protocol running quite smoothly here as well. The sender sends an initial burst of packets, all of which are ACKed a few milliseconds later, followed by another burst, which is ACKed again, on so forth. This is TCP flow control working as intended, quite beautiful indeed!
Conclusion
I my previous posts I designed and implemented a functional circuit for connecting my ESP32-C6's GPIO pins to an Ethernet network, and I implemented a PHY layer using just the GPIO functionality, capable of both transmitting and receiving raw packets.
In this post I implemented a MAC layer on top of that PHY layer, capable of buffering incoming packets efficiently. I then hooked that MAC layer up to the SmolTCP TCP/IP library to gain full internet connectivity. And I ran some realistic throughput tests which showed that the implementation actualy performs quite well, reaching a download throughput of up to 620 kB/s.
This feels like a good place to conclude this series of blog posts on the Niccle project, at least for now. As a reminder, all of the project's code is available on GitHub.
I really enjoyed working on and writing about this project, and over the last six or so months working on it I learned so any new things and got to scratch so many itches.
-
I dove deep into the Ethernet 10BASE-T standard and learned so many interesting things in the process, from the expected shape of a link test pulse, to measuring the propagation speed of an electrical pulse across a cable.
-
I got a chance to design an electrical circuit for completing an Ethernet connection while actually coming to understand the role of each component. I took some detours learning more about transmission lines, differential signaling, and the many different ways you can choose to terminate a transmission line.
-
I dove way too deep into the world of handcrafting assembly code, and spent too many hours staring at and measuring the timing of individual RISC-V instructions under very specific conditions, and staring at said oscilloscope to figure out why the timing of my transmission or receive loop still wasn't quite right.
-
But I also got to experience that little rush of excitement when I finally got it just right and saw that first packet being successfully received, decoded and validated.
-
I got to enjoy using Rust in an embedded software environment for the first time, where I think it shows so much untapped promise. I particularly enjoyed finding the most idiomatic way to express various interfaces and parts of the Niccle stack, even if I was doing it just for the sake of the craft.
Last but not least, I was able to reach the satisfactory conclusion where this little collection of components I put together actually combined to form a complete whole: the world's worst NIC! Capable of connecting to the wider internet through the magic of the Ethernet protocol and TCP/IP (and the amazing SmolTCP crate), and putting up some pretty respectable performance numbers in the process.
I hope you enjoyed reading about the project as much as I enjoyed working on it!

My Niccle breadboarding setup, with some oscilloscope leads still attached.
Footnotes
I also considered using SmolTCP's
RingBuffer
or
PacketBuffer
as the MAC RX queue storage. They can provide similar capabilities to
bbqueue. They are, however, not made to be used concurrently. Which
ultimately didn't make them as good of a fit as bbqueue was.
On the ESP32 family of chips, most of the code in the binary is loaded directly from flash storage into RAM by the CPU when it encounters the code page for the first time. The CPU will cache the page in RAM, but will eventually evict it, and each time it gets (re)loaded from flash this causes a ton of latency. As this recent esp-rs framework issue shows, avoiding such latency in performance-critical code is a problem even for the esp-rs framework itself.